|
2nd Stage:Scene 4 |
特殊なメモリエリア
とはいえ、このメモリに沿って歩いていれば、どこかで再び会えるかもしれない。そう信じることにして、成康はメモリの横をアドレス順に歩いて行くことにした。
いちおう、メモリ内部の数値も確認のために見ていたが、当然のことながらそれを解読することはできない。しかし、トットコトットコ走ってみたり、数バイト分ジャンプしてみたり……と、CPUの気分になって前進することを楽しんでいた。すると、遠くに人影らしきものが見える。
近づくと、それはヒョロリとした木製ロボットだった。トンガリ帽がよく似合う、のほほんとした雰囲気が敵意のないことをうかがわせる。
だが、手には長く鋭いヤリを持ち、見るからに門衛の役割であることがわかる。それが証拠に、成康の前進をキッパリと拒むように、両手で水平にヤリを突き出しているではないかっ!
「ここから先へは行けません!」
「エェ~ッ!? だって、これまでと同じメモリでしょ」
「ここはCPUさえも走らない特殊なメモリなのです!」
「特殊……って、メモリに記憶以外にできることがあるの?」
「質問があればお答えします。聞いてください!」
「見かけは同じメモリなのに、いったいどこが特殊だというの?」
「この先は、メモリ内容が画面に反映されるビデオラムです!」
ビデオラム(VRAM)とは、画面表示に直接関係のある特殊なメモリで、その内容がリアルタイムでディスプレイに反映される。つまり、このメモリの中身を操作すれば、必ず何らかの画面変化をもたらすことになるのだ(←厳密には例外もある)。
ただし、それがどのように画面に反映するか、あるいはVRAMのアドレスはどこか……といった詳細は、機種や個々の画面モードによっても異なっており、一律に論ずることはできない。
|
画面モード 表示エリアの解像度(縦横のピクセル数)や色数などの設定。ユーザーの好みだけでなく、ディスプレイの表示能力に応じた画面モードを選択できるようになっている。 |
ビデオラムは、文字表示のためのテキストVRAM(T.VRAM)と、画像表示のためのグラフィックVRAM(G.VRAM)に大別することができるが、実はコンピュータが誕生したころには画面表示などなかったのだ。
コンピュータの日本語訳が電子計算機となっているように、当初の主たる目的は高速に計算をすることにあった。計算結果は、テレタイプと呼ばれる電信駆動の英文タイプライターでプリントアウトしていたのである。
すでに英文タイプライターでさえ、時代の波に押し流された感があるが、構造的には金属ハンマーの先端に彫られた英数字などを、インクリボンを通して一文字ずつ叩いて印字するというもの。実にメカニカルでクラシカルな代物だ。もちろん、文字サイズやフォントは固定式となる。
|
フォント 文字サイズをも含めて、文字の書体のことをいう。明朝体やゴシック体といったデザイン面と、ポイントや級数で示される大きさで表される。 ディスプレイ表示の場合は、タイプライターと違ってフォントを構成するのはデータだが、文字の再現にはいろいろな方法があるため、そのデータ構造は一様ではない。 |
実際には、英数字の縦横比を2:1としたので長方形のマス目となるが、この1マスに1バイトのメモリを割り当てたものがテキストVRAMの原点である。

文字データ以外にも、テキストVRAMには表示カラーやブリンク(点滅)機能といった表示文字に対する属性(アトリビュート)が割り当てられている。
例えば、Windows系のDOS/Vマシンでは文字とアトリビュートが1バイトずつ交互に並んでいるが、過去には1行ごとにテキストエリアとアトリビュートエリアに分けられている機種もあった。
そういう意味では、図2-4.1は後者の形態ということになるが、ここではアトリビュートについては考慮していない。着目してほしいのは、ディスプレイの1マスに表示されている1バイトの文字データのほうである。
実は、この1バイトの内容はアスキーコードという英数字や制御記号(改行やTabなど)を数値化したものに準拠している。
アスキー(ASCII=American Standard Code for Information Interchange:情報交換のための米国標準記号)の名が示すように、これはアメリカ合衆国仕様の標準コードであり、その他の言語のことは考慮されていない。そして、そのベースになっているのは英文タイプライターである。
すなわち、そこで必要とされたコードは英文タイプライターを電気的に操作するためのものだけであり、1バイトのうちの半分(0~127)でコト足りてしまったのだ。結果として、残り(128~255)は拡張用(未定義)となった。
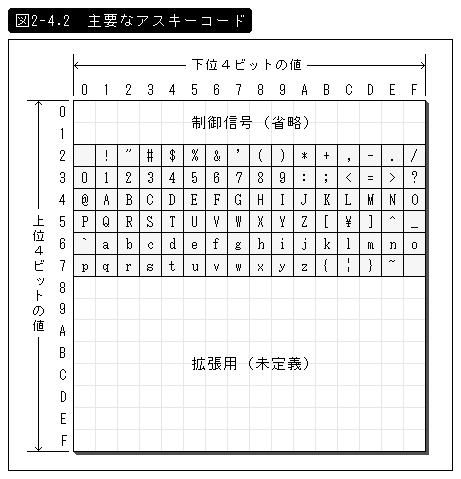
しかし、ただ余らせておくのは「もったいない!」と考えたかどうかはともかく、この部分はパソコンメーカーがそれぞれ独自に罫線や絵文字などの特殊記号を設定するようになっていった。
いわゆる異機種間における文字化けは、このころから発生する宿命にあったといえるだろう。
|
文字化け コンピュータ間で、文字が異なって表現されてしまう現象のこと。拡張用のフォント違いだけではなく、現在では通信障害によるデータの狂いが文字化けとなることが多い。 |
しかし、ここ日本ではひらがなや漢字の表示は決して避けては通れない大命題である。黎明期はともかく、和文タイプライター機能(=日本語ワープロ)がなければ、パソコンは絶対に広く浸透することはできないからだ。
問題は、それを1バイトの半分(拡張用エリア)では物理的に指定することが不可能ということ。かといって、アスキーコードを無視した文字規格では、世界に通用しない陸の孤島のコンピュータになってしまう。
そこで、満を持して登場するのが例の「1バイトで足りなければ2バイトで……」という手法である。
すなわち、アスキーコードの拡張部分の一部を2バイト文字の符号とすることで、日本語文字を表現できるようにしたのだ。
文字サイズも、複雑な日本語に合わせ縦横比=2:2とした。これで、1マス1バイトの半角文字と2マス2バイトの全角文字が混在しても、文字データと表示画面との整合性は保たれることになる。
このような文字データにって作成された文書を日本語テキスト、あるいは単にテキストという。ただし、これを画面に表示するためには拡張された2バイト文字を認識するシステムと、日本語文字のフォントデータが必要になる。
また、前提としてキーボードから漢字へ変換する入力システムも確立されていなければならない。そんなことから、外国製パソコンにとって日本語の存在自体が日本参入への大きな障壁でもあった。
ちなみに、テキストVRAMを使って表示する画面のことをテキスト画面というが、その表示までのプロセスは下図のようになっている。
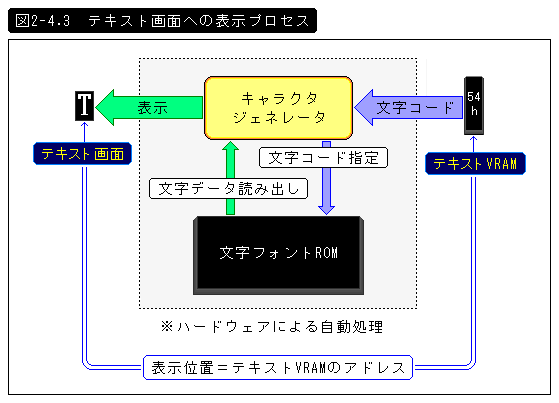
ここでの主役はキャラクタジェネレータ(通称キャラジェネ)だ。キャラジェネは、文字フォントROMから指定文字(=テキストVRAMの内容)に対応する形状データを得て、テキスト画面の指定位置(=テキストVRAMアドレス)に自動的に表示するのだ。
CPUは、画面表示のためのプロセスはまったく気にする必要がない。また、正確にはメモリも特殊というわけではなく、キャラジェネがそのアドレスをVRAMとして認識してればよいのである。
この手軽さこそが、テキスト画面の最大のセールスポイントなのだが、その一方で表示位置の微調整ができないことや、ROMによって固定された文字サイズやフォントに対する不満が、徐々に欠点として浮かび上がってくることになる……。
「フムフム。要は、テキストVRAMという文字表示用のメモリがあるってことでしょ。どうせ覚えきれないから、とりあえずそんなもんでヨシとしようヨ!」
「了解しました。続きは、どうしましょう?」
「続き……って?」
「グラフィックVRAMのことです」
「エッ、堅苦しい話はもうヤメにしたいなァ。先へ進みたいしサッ!」
「了解しました。それでは、そういうことでサヨナラです!」
なんとも実直で無愛想な木製ロボットの対応だった。まるでテキストVRAMという融通のきかない表示システムみたいではないか!
おそらく、この木製ロボットは姿を変えたキャラジェネ……だったのかもしれない。そう考えると性格的に几帳面であることにも納得がいく。とはいえ、単細胞の成康の脳裏にはそんな推察が思い浮かぶわけもなかった。
それよりも、スタコラと引き下がろうとする成康の目の前で、なにやら怪しげな不定形の生物がピョンコピョンコと跳びはねているのだ。こ、これはっ……、もしかするとRPG界最弱の敵・スライムの登場かッ???
|
一時期は、NECのPC-9800シリーズが天下を制していたが、世界的に見れば完全なローカルタイトル。しかも、ネコの目のようにクルクル変わる設計思想やケーブル類に付き合わされていたユーザーは、決してそれに満足していたわけではなかった。 なのに、世界の巨人といわれたIBM(互換機メーカーを含む)をもってしても、そんなローカルタイトルを奪取するのには手間がかかったのである。 その理由のひとつに、ひらがなや漢字を含めた日本語を独立表示するテキスト画面の存在があった。対するIBMの戦略は、複雑な日本語文字を直線や曲線の集まりに分解し、ソフトウェア的にグラフィック画面に表示するという斬新なスタイル! 表示位置も拡大縮小も自在な上に、ソフトウェアによる表示なのでソフトウェアを変えれば世界中の文字に対応できる。もちろん、アプリケーション資産となれば、ローカルチャンピオンの98シリーズとは桁違い……。 こうして、表示位置も拡大縮小もままならないテキスト画面による日本語表示は、過去を継承しようとすればするほど、未来への足かせとなってしまうのであった。そうした紆余曲折を経て、このコラム冒頭の「日本でパソコンといえば……」という状況につながるのである。 |